作为前端开发人员,我们最常用的一些数据结构就是 Object、Array 之类的,毕竟它们使用起来非常的方便。往往有些刚入门的同学都会忽视 Set 和 Map 这两种数据结构的存在,因为能用 set 和 map 实现的,基本上也可以使用对象或数组实现,而且还更简单。
但是 Map 和 Obejct的区别你又知道吗,通过这篇文章你将学习到:
-
Obejct和Map的区别; -
Object中key的顺序; -
Map和Set的基本使用; -
WeakMap和WeakSet使用场景;
Map
在 ECMAScript 6 以前,在 JavaScript 中实现 "键/值"式存储可以使用 Object来方便高效地完成,也就是使用对象属性作为键,再使用属性来引用值。因此 ECMAScript 6 新增了 Map 集合类型。
Map 对象保存键值对,并且能够记住键的原始插入顺序,任何值(对象或者基本类型)都可以作为一个键或一个值。Map 的大多数特性都可以通过 Object 类型实现,但二者之间还是存在一些细微的差异。具体实践中使用哪一个,还是值得细细甄别。
它的特点主要可以归纳为以下几个方面:
-
键可以是任意数据类型:传统对象的键只能是字符串或符号,而 Map 的键可以是任何数据类型,包括对象、函数、基本数据类型等。
-
有序:Map 会记住键值对的插入顺序。这意味着可以按照插入顺序遍历 Map。
-
键值对:Map 存储的元素是键值对,每个键都对应一个值。
基本使用
使用 new 关键字和 Map 构造函数可以创建一个空映射:
const map = new Map();通过查看原型,有以下属性和方法:
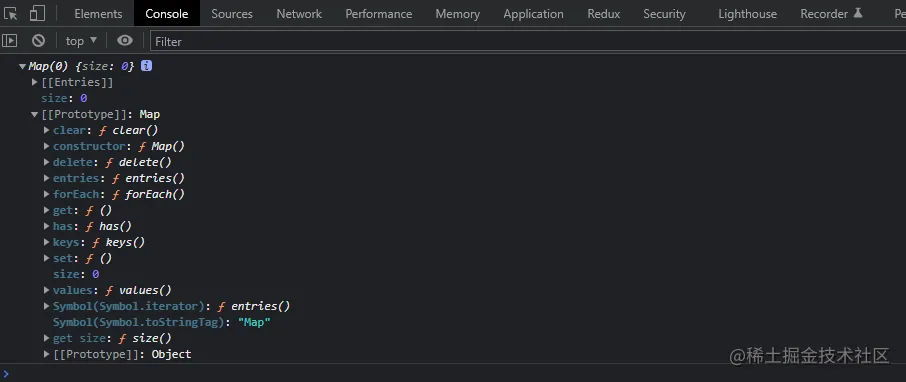
如果想在创建的同时初始化实例,可以给 Map 构造函数传入一个可迭代对象,需要包含 "键/值" 对数组。可迭代对象中途的每个 "键值" 对都会按照迭代顺序插入到新映射实例中:
const map = new Map([
["key1", "val1"],
["key2", "val2"],
["key3", "val3"],
]);
console.log(map.size); // 3通过 size 属性可以获取 Map 对象的键值对的个数,这在 Object 的键值对需要手动计算。
has 和 get
和 Object 类似,Map 对象也可以获取对象是否有这个键以及获取这个键的值,在 Map 中提供了 has(...) 方法和 get(...) 实例方法。其中 has(...) 方法的返回值是一个布尔值,用来表明 Map 对象中是否存在指定的键 key 关联的值,而 get(...) 返回与指定的键 key 关联的值,若不存在关联的值,则返回 undefined,代码如下所示:
const map = new Map([
[1, "val1"],
[2, "val2"],
[3, "val3"],
]);
console.log(map.has("moment")); // false
console.log(map.has("1")); // false
console.log(map.has(1)); // true
console.log(map.get(1)); // val1
console.log(map.get(7)); // undefinedset
在初始化之后,可以使用 set(...) 方法添加 键/值 对,该方法两个参数,一个是 key 作为要添加到 Map 对象的元素的键,该值可以是任何数据类型,一个是 value 作为要添加到 Map 对象的元素的值,该值可以是任何数据类型,代码示例如下:
const map = new Map([["1", "moment"]]);
map.set("1", "你小子");
map.set(-0, "111");
console.log(map); // Map(2) { '1' => '你小子', 0 => '111' }值得注意的是,Map 中的键是唯一的,当初始化时或者 set(...) 方法添加的键,它会首先通过 forEach(...) 方法进行遍历,通过当前的键 key 去查找值 value,如果存在,就重新赋值,如果不存在就添加一个键值对,如果传进来的键是 -0 则会把键设置为 +0 再赋值。
delete
delete(...) 方法用于移除 Map 对象中指定的元素。依然是通过遍历整个记录,查找 delete(...) 方法传进来的参数,如果不为空,则将当前的键和值设为空,并且返回 true,如果不存在这个 key,则返回 false,示例代码如下:
const map = new Map([
["1", "moment"],
["2", "你小子"],
]);
console.log(map); // Map(2) { '1' => 'moment', '2' => '你小子' }
console.log(map.delete("1")); // true
console.log(map.delete(777)); // false
console.log(map); // Map(1) { '2' => '你小子' }clear
clear(...) 方法会移除 Map 对象中的所有元素,该方法首先通过遍历整个 Map 实例,并且将所有的键和值设为空,最后返回的值是 undefined,示例代码如下:
const map = new Map([
["1", "moment"],
["2", "你小子"],
]);
console.log(map.clear()); // undefined顺序与迭代
与 Object 类型相比的一个主要差异是,Map 实例会维护键值对的插入顺序,因此可以根据插入顺序执行迭代操作。 映射实例可以提供一个迭代器(Iterator)能以插入顺序生成 [key, value] 形式的数组。可以 通过 entries(...) 方法或者 Symbol.iterator 属性,它引用 entries() 取得这个迭代器:
const m = new Map([
["key1", "val1"],
["key2", "val2"],
["key3", "val3"],
]);
console.log(m.entries === m[Symbol.iterator]); // true
for (const [key, value] of m.entries()) console.log(key, value);
for (const [key, value] of m[Symbol.iterator]()) console.log(key, value);
// key1 val1
// key2 val2
// key3 val3因为 entries() 是默认迭代器,所以可以直接对映射实例使用扩展操作,把映射转换为数组:
const m = new Map([
["key1", "val1"],
["key2", "val2"],
["key3", "val3"],
]);
console.log(Array.from(m));
console.log([...m]);
// [
// ["key1", "val1"],
// ["key2", "val2"],
// ["key3", "val3"],
// ];forEach
如果不使用迭代器,而是使用回调方式,则可以调用 forEach(...) 方法并传入回调,依次迭代每个 键/值 对。传入的回调接收可选的第二个参数,这个参数用于重写回调内部 this 的值:
const m = new Map([
["key1", "val1"],
["key2", "val2"],
["key3", "val3"],
]);
m.forEach((value, key, map) => {
console.log(key, value, map);
});
// key1 val1 Map(3) { 'key1' => 'val1', 'key2' => 'val2', 'key3' => 'val3' }
// key2 val2 Map(3) { 'key1' => 'val1', 'key2' => 'val2', 'key3' => 'val3' }
// key3 val3 Map(3) { 'key1' => 'val1', 'key2' => 'val2', 'key3' => 'val3' }在上面代码中,key 代表每个迭代的键,value 代表每个迭代的值,而 map 代表当前正在迭代的 Map 实例。
keys
keys(...) 返回一个引用的迭代器对象。它包含按照顺序插入 Map 实例对象中每个元素的 key 值。具体代码实例如下:
const m = new Map([
["key1", "val1"],
["key2", "val2"],
["key3", "val3"],
]);
console.log(m.keys()); // [Map Iterator] { 'key1', 'key2', 'key3' }values
values(...) 方法返回一个新的迭代器对象。它包含按顺序插入 Map 实例对象中每个元素的 value 值,具体代码如下:
const m = new Map([
["key1", "val1"],
["key2", "val2"],
["key3", "val3"],
]);
console.log(m.values()); // [Map Iterator] { 'val1', 'val2', 'val3' }Map 和 Object 的区别
了解 Map 和 Object 的区别对我们开发者很重要,这不仅是面试中经常被问到的话题,而且对于在乎内存和性能的开发者来说,Object 和 Map 之间确实存在着显著的差别。
继承
Map 对象继承自 Object 对象,你可以通过原型继承去调用 Object 身上的原型方法,例如:
const m = new Map([["key3", "val3"]]);
console.log(m.toString()); // [object Map]在上面的代码,map 是 Map 对象的实例对象,而 Map 对象继承自 Object,而创建的普通对象是 Object 的实例对象,我们只需查找一次便可以查找到顶层对象 Object,具体代码如下所示:
const m = new Map([["key3", "val3"]]);
const obj = {};
console.log(m.__proto__.__proto__.constructor === obj.__proto__.constructor);
// true创建实例
创建 Map 实例只有一种方式,就是使用其内置的构造函数以及 new 语法,而创建对象则有多种方法,具体代码示例如下:
const m = new Map([["key", "value"]]);
const object = {...};
const object = new Object();
const object = Object.create(null);而通过使用 Object.create(null) 来创建的对象,它可以生成一个不继承 Object.prototyoe 的实例对象。
迭代
通过 Map 创建出来的实例对象能通过 for...of 方法进行遍历,而普通对象则不能,但是能通过 for...in 方法去枚举所有的 key,要想查看当前对象是否可以被 for...of 遍历,我们通过查看该对象本身是否有定义了 Symbol.Iterator 方法,,如果存在则可以变遍历:
const map = new Map();
const object = {};
console.log(map[Symbol.iterator]); // [Function: entries]
console.log(object[Symbol.iterator]); // undefined通过上面的代码可以看出,普通的对象并没有定义 Symbol.Iterator 方法,输出为 undefined。详情可以看这篇文章 跳转链接 。
普通对象可以眼使用Object.keys(obj)只能获取所有 key 并进行遍历:
const object = {
a: 1,
1: 2,
foo: "moment",
};
console.log(Object.keys(object)); // [ '1', 'a', 'foo' ]该方法返回一个由 key 组成的数组,可以通过该数组进行遍历。
key 的有序和无序
在 Map 中,key 的顺序是按插入时间进行排序的:
const m = new Map([
["key1", "val1"],
["key2", "val2"],
["key3", "val3"],
[1, "val4"],
]);
console.log(...m.keys()); // key1 key2 key3 1但是在普通对象中就不同了,在最开始学习 JavaScript 的时候,我们一直被灌输 Object 中的 key 是无序的,不可靠的,而与之相对的是 Map 实例会维护 键/值对 的插入顺序。
在一些现代的浏览器当中,key 的输出顺序是可以预测的:
-
如果当前的
key是整数或者0,就按照自然数的大小进行排序; -
如果当前的
key是字符类型的,则按照加入的时间顺序进行排序; -
如果当前的
key是Symbol类型的,则按照加入的时间顺序进行排序; -
如果是以上类型的相互结合,结果是先按照自然数升序进行排序,然后按照非数字的
string的加入时间排序,然后按照Symbol的时间顺序进行排序,也就是说他们会先按照上述的分类进行拆分,先按照自然数、非自然数、Symbol的顺序进行排序,然后根据上述三种类型下内部的顺序进行排序。
具体代码演示如下所示:
const object1 = {
1: 111,
3: 3333,
2: 222,
};
const object2 = {
a: 111,
c: 3333,
b: 222,
};
const object3 = {
[Symbol("1")]: "first",
[Symbol("3")]: "second",
[Symbol("2")]: "last",
};
const result = {
[Symbol("你小子")]: "moment",
1: 1111,
aaa: "牛逼",
};
console.log(Reflect.ownKeys(object1)); // [ '1', '2', '3' ]
console.log(Reflect.ownKeys(object2)); // [ 'a', 'c', 'b' ]
console.log(Reflect.ownKeys(object3)); // [ Symbol(1), Symbol(3), Symbol(2) ]
console.log(Reflect.ownKeys(result)); // [ '1', 'aaa', Symbol(你小子) ]键的值
在 Map 对象中,该对象的 key 可以是任何类型的值,而在普通对象中的 key 只能是 string 类型(number类型会自动转变成 string 类型)和 Symbol 类型,如果传进来的是复杂类型会自动报错:
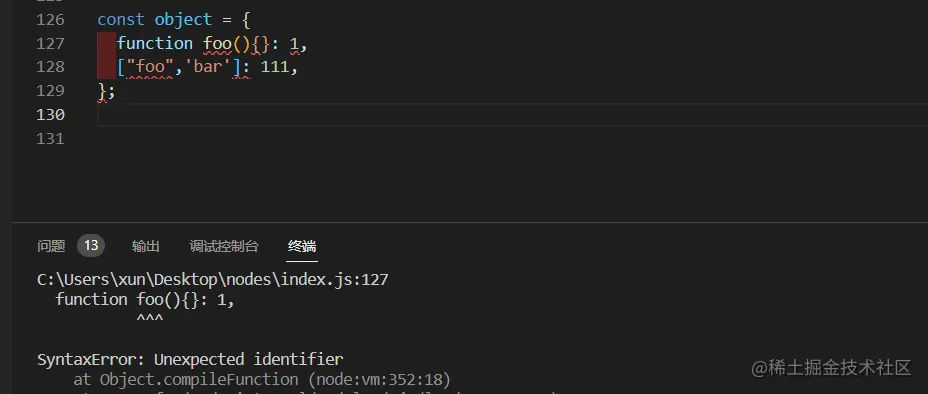
选择 Object 还是 Map
在选择 Object 还是 Map 时,需要考虑具体的应用场景,特别是从 内存占用、插入性能、查找速度 和 删除性能 四个方面进行分析。虽然 Object 和 Map 都用于存储键值对,但它们在不同场景下的表现有所不同,了解这些差异可以帮助我们做出更合适的选择。
内存占用
Object:Object 在内部实现上通常是简单的哈希表。它的内存开销较小,尤其在处理简单的键值对时,但它会使用一些额外的内存来处理原型链(继承的属性)和一些内部操作。Object 对象本身只支持字符串和符号类型的键,而对其他类型(如对象、函数等)作为键时会自动转换为字符串。
Map:Map 作为一个标准的键值对集合,支持更复杂的数据类型作为键(包括对象、函数、基本类型等),并且它专门为存储键值对进行优化。因此,Map 在内存使用上可能会稍大一些,尤其是在存储大量键值对时。但由于 Map 没有像 Object 那样的原型链,它的内存管理更直接和高效。
如果对内存要求严格且数据量较小,且键是字符串或符号,Object 更加节省内存;如果需要更高的灵活性,尤其是当键是非字符串类型时,Map 是更好的选择,虽然内存占用稍大。
插入性能
Object:Object 在插入新的键值对时,通常是基于哈希表的,因此插入操作的时间复杂度接近 O(1)。然而,Object 的性能会受到属性名(键)的限制,尤其是当你使用的键是字符串时。如果插入的数据量较大,或者键名非常复杂时,性能可能受到影响。
Map:Map 在设计上专门优化了键值对的存储和操作,它的插入性能通常优于 Object,尤其是当键是对象、函数等复杂数据类型时。Map 使用自定义的哈希算法来处理不同类型的键,从而提供稳定和高效的插入性能。插入操作的时间复杂度一般为 O(1),即使在插入大量键值对时,性能也通常保持较好。
如果频繁进行插入操作并需要处理各种数据类型的键,Map 提供更好的性能;而对于简单的插入操作和基本类型的键,Object 的插入性能也足够高效。
查找速度
Object:Object 的查找操作是基于哈希表实现的,查找性能也接近 O(1)。但是,由于 Object 的键只能是字符串或符号类型,若要查找复杂类型的键(如对象、函数等),Object 需要将这些键自动转换为字符串,这可能导致性能的降低。
Map:Map 的查找操作经过专门的优化,尤其是当键是复杂数据类型(如对象、函数等)时,它能够直接使用这些键进行哈希查找,性能通常比 Object 更高。在大量数据下,Map 的查找性能通常优于 Object。
如果需要频繁查找复杂类型的键值对,Map 提供更好的性能;而对于简单的字符串或符号键,Object 的查找速度也非常快,几乎没有性能瓶颈。
删除性能
Object:Object 对键值对的删除操作也是基于哈希表实现的,通常删除性能为 O(1)。但是,由于 Object 的键仅限于字符串或符号类型,如果需要删除某个键,JavaScript 引擎需要重新计算哈希值,这可能会导致在某些情况下的性能波动。
Map:Map 的删除操作同样经过优化。Map 提供了高效的删除操作,其删除性能通常也为 O(1),并且由于 Map 是专门为键值对操作设计的,它在处理大量数据时的删除性能比 Object 更加稳定。
在频繁删除键值对的场景中,Map 在处理大量数据时更高效和稳定,而 Object 在大量删除时性能可能有所波动。
综合比较
| 特性 | Object | Map |
|---|---|---|
| 内存占用 | 内存占用较小,但会受到原型链和键限制的影响 | 内存占用稍大,但处理键时更为灵活和高效 |
| 插入性能 | 插入性能一般,尤其是在键为字符串时 | 插入性能优秀,尤其是处理复杂类型的键时 |
| 查找速度 | 查找性能接近 O(1),但在处理复杂键时稍慢 | 查找性能优越,尤其是复杂键类型时表现更好 |
| 删除性能 | 删除性能良好,但在复杂情况下可能稍慢 | 删除性能稳定,适用于频繁的删除操作 |
Object 和 Map 的应用场景
即使 Map 相对于 Object 有很多优点,但是依然存在某些使用 Object 会更好的场景,毕竟 Object 是 JavaScript 中最基础的概念。
选择 Object 的场景
- 键仅限于字符串或符号类型,且数据量较小:
const person = {
name: 'Moment',
age: 30,
};
console.log(person.name); // "Moment"- 对内存占用敏感且对插入、查找性能要求不高:
const user = {
id: 1,
username: 'Moment',
email: 'Moment@example.com',
};
console.log(user.username); // "Moment"- 需要与旧版 JavaScript 库或 API 兼容(如某些老旧的 API 要求使用
Object):
// 示例:某些旧的 API 或库可能需要使用 Object
const obj = Object.create(null); // 创建一个没有原型链的对象
obj.key = 'Moment';
console.log(obj.key); // "Moment"选择 Map 的场景
- 需要支持多种数据类型作为键(如对象、函数、基本数据类型等):
const map = new Map();
map.set(1, 'Number');
map.set('key', 'String');
map.set([1, 2], 'Array');
map.set({ name: 'John' }, 'Object');
console.log(map.get(1)); // "Number"
console.log(map.get('key')); // "String"
console.log(map.get([1, 2])); // undefined, 因为引用不同- 需要频繁进行插入、查找、删除操作,且数据量较大:
const largeMap = new Map();
for (let i = 0; i < 100000; i++) {
largeMap.set(i, `Value ${i}`);
}
console.log(largeMap.get(99999)); // "Value 99999"- 需要保持插入顺序,或者需要稳定的性能:
const map = new Map();
map.set('first', '1st');
map.set('second', '2nd');
map.set('third', '3rd');
for (let [key, value] of map) {
console.log(`${key}: ${value}`);
}
// 输出:
// first: 1st
// second: 2nd
// third: 3rd- 需要高效处理大量键值对,特别是当键是复杂类型时:
const complexMap = new Map();
const obj1 = { id: 1 };
const obj2 = { id: 2 };
complexMap.set(obj1, 'Object 1');
complexMap.set(obj2, 'Object 2');
console.log(complexMap.get(obj1)); // "Object 1"
console.log(complexMap.get(obj2)); // "Object 2"- 需要进行复杂的迭代操作,如按插入顺序遍历键值对:
const map = new Map();
map.set('apple', 1);
map.set('banana', 2);
map.set('cherry', 3);
// 使用 forEach 进行迭代
map.forEach((value, key) => {
console.log(`${key}: ${value}`);
});
// 输出:
// apple: 1
// banana: 2
// cherry: 3小结
Object 适用于简单数据存储和内存敏感场景,尤其在需要与旧版 JavaScript 库兼容时;而 Map 适用于复杂数据存储,特别是当键类型更灵活或操作频繁时,提供更好的性能和功能。
Set
ECMAScript 6 新增的 Set 是一种新集合类型,为这门语言带来集合数据结构。Set 在很多方面都像是加强的 Map,这是因为它们的大多数 API 和行为都是共有的。
Set 的基本使用
因为 Set 的 API 和 Map 的一致,这里就不详细讲了,值得注意的是 Set 对象没有 get(...) 方法,使用代码如下:
const s = new Set(["val1", "val2", "val3"]);
s.add(111);
s.delete("val1");
console.log(s.has("val1")); // false
console.log(s.values()); // [Set Iterator] { 'val2', 'val3', 111 }
console.log(s.keys()); // [Set Iterator] { 'val2', 'val3', 111 }
s.forEach((key, value) => {
console.log(key, value);
});
// val2 val2
// val3 val3
// 111 111Set 使用场景
在日常开发中,我们可以通过使用 Set 进行数组去重:
const result = [1, 2, 3, 4, 5, 5, 6, 7, 7, 7, 8];
console.log([...new Set(result)]); // [1, 2, 3, 4, 5, 6, 7, 8];WeakMap
es6 新增的 WeakMap 对象是一种新的集合类型,它一组 键/值对 的集合,其中的键是弱引用的。其键必须是对象,而值可以是任意的。WeakMap 是 Map 的兄弟类型,其 API 也是 Map 的子集。WeakMap 中的 weak(弱),描述的是 JavaScript 垃圾回收程序对待 弱映射 中键的方式。
基本使用
WeakMap 是一个构造函数,所以在实例化的时候必须使用 new 关键字,否则会报 TypeError 的错误:
const m = WeakMap(); // TypeError: Constructor WeakMap requires 'new' at WeakMap如果想在实例化的时候填充弱映射,则构造函数可以接收一个可迭代对象,其中需要包含 键/值对 数组:
const obj1 = { nickname: 77 };
const obj2 = { nickname: "moment" };
const map = new WeakMap([
[obj1, 77],
[obj2, "moment"],
]);
console.log(map.get(obj1)); // 77
console.log(map.get(obj2)); // moment但是如果键使用的是原始值则会报错:
const m = new WeakMap();
m.set("1", "1111");
const m = new WeakMap();
m.set("1", "1111");
// TypeError: Invalid value used as weak map key at WeakMap.setWeakMap 有以下的方法可供使用,和 Map 对应的 API 的功能一致:

弱键
在 WeakMap 中,“weak” 表示键是以 弱引用 的方式存储的,也就是说,这些键不会阻止垃圾回收。当键没有其他引用时,它会被自动清除。然而,WeakMap 中的值是强引用,只要键存在,键值对就会在映射中保留,值不会被垃圾回收。
来看下面的例子:
const map = new WeakMap();
map.set({}, '777');在这个例子中,set(...) 方法将一个新对象作为键,并将字符串 "777" 作为对应的值。由于没有其他引用指向这个对象,当代码执行完成后,这个对象将会被垃圾回收。相应的,WeakMap 中的键值对也会被自动删除,导致 WeakMap 变为空映射。因为键和对应的值都没有被引用,值本身也会成为垃圾回收的目标。简而言之,WeakMap 中的键是弱引用,不会阻止垃圾回收,如果键被回收,键值对也会被移除。
const wm = new WeakMap();
const container = {
key: {},
};
wm.set(container.key, 'val');
function removeReference() {
container.key = null;
}在这个例子中,container 对象持有对 WeakMap 键的引用,因此该键不会被垃圾回收。然而,当调用 removeReference() 后,container.key 的唯一引用被清除,垃圾回收程序会清除该键及其对应的值。
WeakMap 的特殊结构使得其键只有在没有其他引用时才有效。由于弱引用的特性,WeakMap 中的键不可枚举。如果键是可枚举的,其列表会受垃圾回收机制的影响,导致不可预测的结果。在某一时刻,键可能存在,但在垃圾回收发生后,键会消失,因此无法依赖 WeakMap 进行键的遍历。🤣🤣🤣
WeakMap 示例
因为 WeakMap 示例不会妨碍垃圾回收,所以非常适合保存关联元数据,来看下面这个例子:
const button = document.querySelector("button");
const result = [button, "你小子"];
result = null;当我们不需要的时候需要手动设置 null 对其进行接触引用,这样释放引用的写法很不方便,造成没必要的代码.一旦忘了写,就会造成内存泄漏。
WeakMap 的诞生就很好的解决了这个问题,一旦不再需要,WeakMap 里面的键名对象和所对应的 键/值对会自动消失,不用手动删除引用,具体代码实例如下:
const map = new WeakMap();
const button = document.querySelector("button");
map.set(button, "又是你小子");
console.log(map.get(button)); // 又是你小子在这个时候 WeakMap 里面对 button 的引用就是弱引用,不会被计入垃圾回收机制,但当节点从 DOM 树中被删除后,垃圾回收程序就可以立即释放其内存,WeakMap 中的键也就不存在了。
再举一个例子 🌰🌰🌰 当我们需要在不修改原有对象的情况下存储某些属性等,但是又不想管理这些数据是,可以使用 WeakMap:
const cache = new WeakMap();
function storage(obj) {
if (cache.has(obj)) return cache.get(obj);
else {
const length = Object.keys(obj).length;
cache.set(obj, length);
return length;
}
}WeakSet
WeakSet 对象也是和前面的 WeakMap 一样,不会影响垃圾回收,并且也是只能是对象的集合,不能像 Set 那样可以是任何类型的任意值,它也具有 Set 部分 Api:

因为这些 API 和前面讲到的基本没什么区别,这里就不再进行讲解。
我们来考虑一下这样一个场景,我们需要一个数组来保存着被禁止掉的 DOM 元素:
const disabledElements = new Set();
const loginButton = document.querySelector('button');
// 通过加入对应集合,给这个节点打上“禁用”标签
disabledElements.add(loginButton);通过上面的例子查询元素在不在 disabledElements 中,就可以知道它是不是被禁用了,但是假如
元素从 DOM 树中被删除了,它的引用却仍然保存在 Set 中,它的键依然引用着,因此垃圾回收程序也不能回收它,这就很容易造成内存泄漏。
使用 WeakSet 对象就很好的解决了这个问题:
const disabledElements = new WeakSet();
const loginButton = document.querySelector('#login');
// 通过加入对应集合,给这个节点打上“禁用”标签
disabledElements.add(loginButton);这样只要 WeakSet 中任何元素从 DOM 树中被删除,垃圾回收程序就可以忽略其存在,而立即释放其内存。
js 中 map 的底层实现
map 是一个数据结构,保存了 key-value,即键-值对,每个键映射到一个值,map 可以按照元素插入的顺序进行遍历,这是如何实现的呢?
在 js 中,map 是由哈希表(hashmap) 实现的,下面我们来介绍一下 hashmap 的组成。
哈希表
一般情况下,哈希表由数组 + 链表的形式组成,综合了两者的优势,使得寻址、插入、删除都比较方便。为什么是一般情况?在 JDK 8 开始,某链表达到阈值会将链表结构转换为红黑树结构,我们在后面细说。
我们可以看看最常见的格式:数组 + 链表。

hashmap 深入
一个优秀的哈希函数需要注意什么?
哈希函数的设计相当重要,一般情况下我们需要考虑这些内容:
- 均匀分布:
- 好的哈希函数会使得键在哈希表中的分布尽可能均匀,也就是说,任何小的改动(比如改变键的一个字符)都将会产生一个完全不同的哈希值。这样就可以最大程度地减少哈希冲突,使得哈希表的性能更优。
- 同时也可以防止恶意攻击者通过故意构造碰撞来破坏哈希表的性能。
- 计算效率:哈希函数的计算过程应该尽可能高效,以便能在
O(1)时间内完成键到索引的映射。 - 不可逆性:哈希函数应该是单向的,即从哈希值无法还原出原始的输入数据。这是为了保护数据的安全性,防止敏感信息被恢复出来。
- 可扩展性:哈希函数应该能够适应不同规模的数据集,无论是小型还是大型数据集,都能够保持较好的性能。
hashmap 的 set 过程
hashmap 的 set 过程为:
首先判断 key 是否为空,若不为空则计算 key 的 hash 值:
- 根据 hash 值计算在数组中的索引位置。
- 如果数组在该位置有值,则通过比较是否存在相同的 hash 值(即相同的 key 值)。
- 若存在则将新的 value 覆盖原来的 value。
- 不存在则将该 key-value 保存在链头。
- 若数组在该处没有元素,则直接保存。
hashmap 的 get 为什么是 O(1)
hashmap 在寻找指定的 key 时,若 key 不为空,则会先计算 key 的 hash 值,随后根据 hash 值搜索在数组中的索引位置。
这一步很多人以为是 O(n),但其实 index = hash mod x,相关的 value 会直接存在 index 中,其中 x 一般被设计为当前数组被开辟的空间长度。
这也是为什么 hash 值通常为素数,这能更好地把 hash 值均匀分布在整个 hashmap 中,减少冲突。
当遇到冲突时,会在数组对应位置的链表头部插入(最先保存的元素放在链尾),考虑到冲突,其实 get 最坏的情况甚至可以到达 O(n),这种情况可以用红黑树替换链表结构,将查找时间稳定在 O(logn),但红黑树的副作用也恰恰体现在无论如何都会 O(logn)。
面对 O(n) 的极端情况,hashmap 会通过设计尽量避免 hash 值的冲突,所以一般就认为是 O(1)。
hashmap 扩容机制
hashmap 一开始创建时,原始数组的大小可以事先设定,后续会基于一个机制,进行动态扩容。
比如基于 JDK 的 hashmap 设计,创建时默认的初始容量为 16(就是数组的长度),每一次扩容时,容量翻倍,扩充通常在填充因数达到一定阈值时进行。
填充因数:已存储元素/容量,JDK 默认阈值位 0.75,这是一个权衡了时间和空间成本的折中方案。
达到阈值并扩充时,原本数组中的元素会重新计算其在新数组中的位置,并重新插入,在数据量较大时,存在一定性能上的挑战。
注意!javascript 中的规范和 JDK 不同,但没有相关的数据。默认的空间、填充因数等都是通过内部的一个计算逻辑得到的。
大数据扩容的优化策略
面对大数据扩容时,我们可以考虑以下几种优化策略:
- 并发扩容:将扩容过程分解成更小的任务,并允许他们在可用的处理器上并发运行,每一次扩容操作只对其中一个段进行,从而适度减少了单次扩容的计算量。
- 分步扩容:并非一次将所有的数据移到新的位置,而是在每次添加新元素时,将一部分已有元素移到新的位置。这种方式可以将扩容操作的负担分散在其他操作中,从而避免一次性完成所有重哈希操作带来的性能压力。
- 预先扩容:如果能预估到数据较多,可以提前选取一个大的初始大小,避免在运行过程中频繁的扩容操作。
- 选择合适的填充因数。
红黑树的出现时机与副作用
在 JDK 8 后,当 hashmap 中元素的数量大于一定阈值(默认为 64)并且要插入的元素在链表中的位置大于 TREEIFY_THRESHOLD(默认为 8)时,会将链表转为红黑树,这样可以提高搜索速度,避免性能下降。
红黑树是一种自平衡的二叉搜索树,它在插入和删除节点时通过一系列的旋转和重新着色操作来保持树的平衡。它得名于节点上的颜色标记,每个节点可以是红色或黑色。
红黑树的特性使得树的高度保持在较小的范围内,从而保证了插入、删除和查找操作的时间复杂度都是 O(log n),但这恰恰是一个副作用 —— 查找时间限制到了 O(log n),当冲突较少时这反而是个弊端。
至于红黑树的具体特性?我认为不用这么深入了,如果感兴趣可以看看其他大佬的文章 🫡。
总结
这篇文章深入探讨了 Map、Object 和 Set 在 JavaScript 中的特点和使用场景。Object 是一种基础的键值对存储结构,适用于简单的字符串键和小规模数据,且内存占用较低;而 Map 提供了更高的灵活性,支持任何类型的键,并且保持插入顺序,适用于复杂数据和频繁操作的场景。Set 则用于存储唯一值,常用于去重和集合操作。Map 和 Set 在性能和功能上优于 Object,尤其在处理大量数据时,提供了更好的稳定性和效率。同时,WeakMap 和 WeakSet 通过弱引用避免内存泄漏,进一步优化了内存管理。