在 CommonJS 之前,JavaScript 在模块化方面没有统一的标准,各种不同的解决方案在不同环境中被使用。以下是一些常见的早期模块化方式:
-
浏览器端的
script标签
早期的浏览器端 JavaScript 代码通常通过<script>标签引入多个 JavaScript 文件,代码之间没有明确的模块化,所有内容都放在一个全局作用域中。这导致了命名冲突和维护难度。<script src="module1.js"></script> <script src="module2.js"></script> -
立即执行函数表达式(IIFE)
为了避免全局命名冲突,开发者使用了 IIFE(立即执行函数表达式)来创建局部作用域,从而避免污染全局命名空间。(function () { var module = {}; module.sayHello = function () { console.log('Moment!'); }; // 其他模块代码 })(); -
AMD(Asynchronous Module Definition)
在浏览器端,随着应用程序复杂度的增加,AMD 提出了异步加载模块的方式。比如 RequireJS 库就是基于 AMD 规范,允许模块异步加载和管理依赖关系。define(['module1', 'module2'], function (module1, module2) { // 模块定义 }); -
CMD(Common Module Definition)
由 SeaJS 提出的规范,CMD 主要针对浏览器端模块化,它和 AMD 类似,但强调同步加载和更简洁的依赖声明。define(function (require, exports, module) { var module1 = require('module1'); exports.sayHello = function () { console.log('Hello Moment!'); }; });
这些方式各自存在一些局限性,尤其是在服务器端开发中缺乏统一的模块化标准。CommonJS 提出了一个统一的标准,尤其在 Node.js 中得到了广泛应用,允许通过 require 导入模块,通过 module.exports 导出模块,实现了更简洁、同步的模块化机制。
CommonJs 的基本使用
CommonJS 的基本使用主要围绕模块的导入和导出。它提供了两个核心方法:
-
module.exports:用于导出模块,使其能够在其他文件中被 require 引入。
-
require:用于导入其他模块,获取其导出的内容。
导出模块
在 CommonJS 中,你通过 module.exports 来定义一个模块的公开接口。这意味着其他文件可以使用 require 来引入这个模块。
假设我们创建一个名为 math.js 的模块,它包含一个加法函数。
// math.js
function add(a, b) {
return a + b;
}
// 导出模块
module.exports = {
add: add,
};或者,你可以直接导出一个对象或函数:
// math.js
module.exports = function (a, b) {
return a + b;
};如果你想导出多个成员(例如函数、对象、变量等),可以通过 module.exports 或 exports 对象来实现。
// utils.js
exports.sayHello = function () {
console.log('Hello!');
};
exports.sayGoodbye = function () {
console.log('Goodbye!');
};导入模块 (require)
你可以使用 require 导入其他模块的内容。require 会读取并执行指定的模块文件,并返回模块导出的内容。
假设在另一个文件中,我们需要使用 math.js 模块中的加法函数。
// app.js
const math = require('./math'); // 导入 math 模块
console.log(math.add(2, 3)); // 输出 5Node.js 提供了一些内置模块,例如 fs(文件系统)、http(HTTP 服务)等,可以直接通过 require 导入使用。
// 使用内置的 http 模块创建一个简单的服务器
const http = require('http');
const server = http.createServer((req, res) => {
res.write('Hello, world!');
res.end();
});
server.listen(3000, () => {
console.log('Server running at http://localhost:3000/');
});在 CommonJS 中,模块通过 module.exports 或 exports 导出内容;通过 require 导入其他模块并使用其导出的功能。
深入理解 CommonJs 的导出
在 commonjs 中每个模块对应就是 Module 示例,如下代码所示:
// 此类继承的是 WeakMap
const moduleParentCache = new SafeWeakMap();
function Module(id = "", parent) {
this.id = id; // 模块的识别符,通常是带有绝对路径的模块文件名
this.path = path.dirname(id); // 文件当前的路径
/
* 相当于给构造函数 Module 上添加了一个 exports 为空对象
* 等同于这样的写法 Module.exports = {};
*/
setOwnProperty(this, "exports", {});
// 返回一个弱引用对象,表示调用该模块的模块
moduleParentCache.set(this, parent);
updateChildren(parent, this, false);
this.filename = null; // 模块的文件名,带有绝对路径
this.loaded = false; // 是否已经被加载过,用作缓存
this.children = []; // 返回一个数组,表示该模块要用到的其他模块
}在 CommonJS 中,每个模块都有一个独立的实例,包含如 id、exports、filename、loaded 和 children 等关键属性,这些属性用于管理模块的生命周期和依赖关系。Module 构造函数用于表示模块对象,封装了模块的基本信息和状态。
每个模块通过 exports 对象来暴露其接口(功能或数据),exports 最初是一个空对象(如同代码中的 setOwnProperty(this, 'exports', {})),开发者可以在模块内部向 exports 对象添加内容。
moduleParentCache.set(this, parent) 通过 WeakMap 追踪模块与父模块之间的关系,确保正确建立模块的父子依赖。WeakMap 的作用是防止内存泄漏,因为当父模块不再引用子模块时,子模块的引用会被自动删除。这体现了 CommonJS 模块系统中的依赖树,模块间的关系通过引用管理,同时不会阻止垃圾回收。
updateChildren(parent, this, false) 这一行代码将当前模块添加到父模块的 children 列表中,表示父模块依赖子模块。CommonJS 模块系统中的依赖关系是单向的:父模块依赖子模块,而子模块无法反向依赖父模块。
loaded 标志用于标识模块是否已加载,以避免重复加载。在 Node.js 中,模块采用缓存机制,模块代码只会在首次加载时执行,之后的 require 调用会直接返回缓存中的模块实例。此段代码模拟了这一缓存机制,确保模块在多次加载时不会重复执行。
通过打印 module,有以下的输出,也证实了上边所讲的:
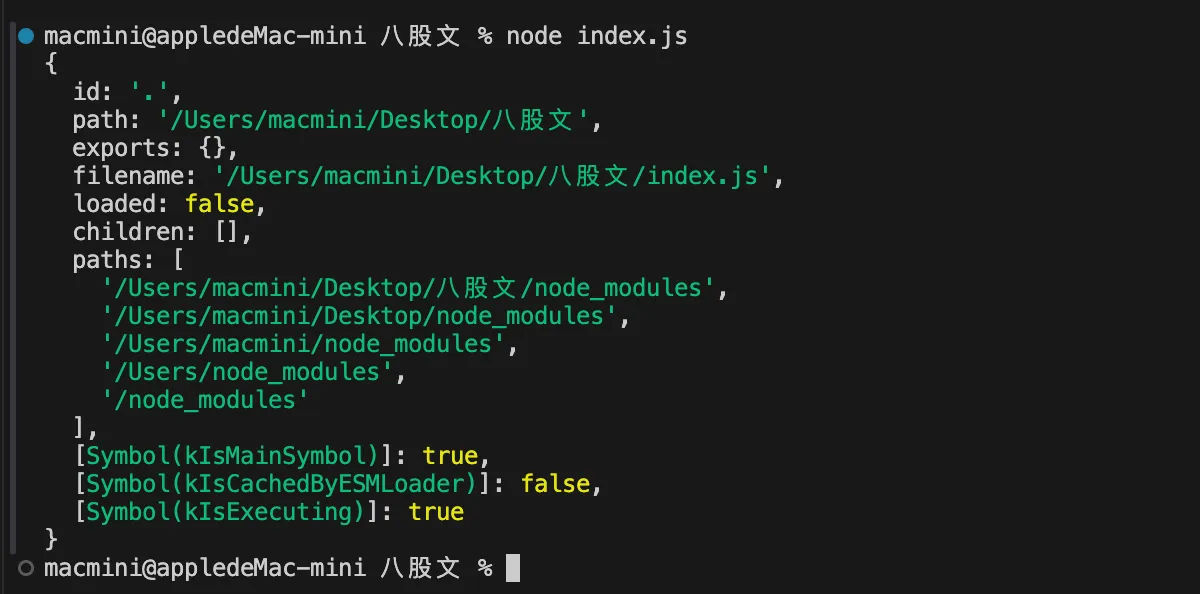
这里定义了一个数组 wrapper,里面存了一个 匿名函数,但是这个 匿名函数 被拆分成了头和尾两段,而这就是为下面进行头尾封装的辅助数组。

Node.js 对 JavaScript 的代码快进行了首为包装,我们所编写的代码将作为包装函数的执行上下文,使用的 require、exports、module 本质上是通过形参的方式传递到包装函数中的,而这就是 Node.js 中定义的包装函数:

假设我们有这样的代码:
// 模块导出
function foo(x, y) {
return x + y;
}
module.exports = {
foo,
};借助上面例子的 foo 函数,在编译的过程中,将 JavaScript 的代码以形参的形式传入 wrap 函数,对 foo 函数进行进行头尾包装,它包装的之后的样子如下:
(function (exports, require, module, __filename, __dirname) {
function foo(x, y) {
return x + y;
}
module.exports = {
foo,
};
});这样每个模块文件之间都进行了作用域隔离。包装之后的代码会通过 vm 原生模块的 runInThisContext() 方法执行(类似 eval,只是具有明确上下文,不污染全局),返回一个具体的 function 对象。最后,将当前模块对象的 exports 属性, require() 方法, module(模块对象自身),以及在文件定位中得到完整文件路径和文件目录作为参数传递给这个 function() 执行。
通过这样的方法,Node.js 实现了以下目的:
-
将顶级变量,例如:
var、const、或者let等顶级变量限定为模块而不是全局对象; -
它有助于提供一些实际特定于模块的全局变量,例如:
__firename、dirname,模块开发者可以使用模块和对象从模块导出值;
module.exports 和 exports 的关系
前面讲到,module.exports === exports 为 true,通过打印也确实如此。
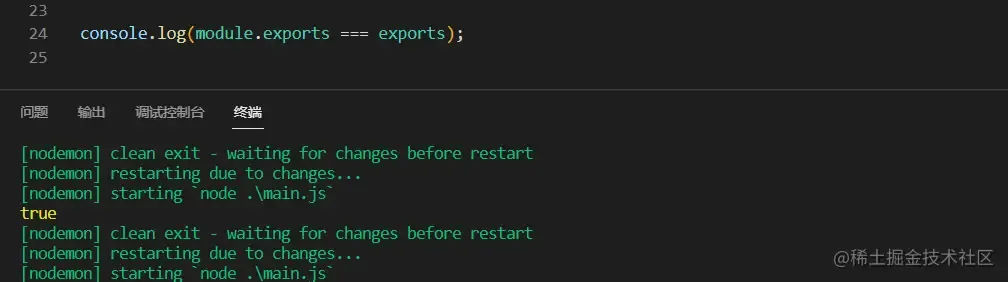
在 _compile 原型方法上定义了一个 exports 用来保存 Module.exports,所以这也就是为什么 module.exports === exports 的原因了,实际上是它们共享同一块内存空间。

注意: 虽然他们共享的是同一块内存空间,但是最终被导出的是 module.exports 而不是 exports。值得注意的是 CommonJs 导出的是对象的引用,通过 require 之后 可以对其进行修改。
如下代码所示:
// a.js 文件下
const object = {
moment: 'Moments',
};
setTimeout(() => {
object.moment = 'Mayday';
}, 2000);
module.exports = {
object,
};
// main.js 文件下 通过node ./main.js运行
const bar = require('./a');
console.log('main.js', bar.object.moment); // main.js Moments
setTimeout(() => {
console.log('2秒之后输出 ', bar.object.moment); // 2秒之后输出 2秒之后输出 Mayday
}, 2000);一些错误的做法
// a.js 文件下
const object = {
moment: 'Melody',
};
exports = {
object,
};
// main.js 文件下 通过node ./main.js运行
const bar = require('./a');
console.log(bar); //{}这样的写法,实际上是给 exports 另外创建了一个对象,但是这时候 exports 已经和 module.exports 脱离关系了,它并没有对 module.exports 所在的内存执行实际的操作,此时依然为空对象,所以最终输出的是空对象。再看一下带代码:
// a.js 文件下
const object = {
moment: 'Moment',
};
exports.object = object;
// main.js 文件下 通过node ./main.js运行
const bar = require('./a');
console.log(bar); // { object: { moment: 'Moment' } }这段代码实际上就是给 module.exports 添加了一个对象 object,所以最终能看到想要的输出。
CommonJS 模块输出的是一个值的拷贝,修改修改引入的值不会改变原来的模块:
// main.js
var { moment } = require('./foo.js');
console.log(moment);
setTimeout(() => {
moment = 777;
}, 1000);
setTimeout(() => {
console.log('输出的是缓存的值', moment);
}, 4000);
// foo.js
var moment = 'moment';
setTimeout(() => {
console.log('输出的是原本的值,不会因为子模块修改而改变', moment);
}, 2000);
setTimeout(() => {
moment = '不会修改 main 导入的值';
}, 3000);
exports.moment = moment;运行 main.js,毫无悬念,模块foo被 main.js 导入之后,修改 foo 的值不会,不会引起 main.js 导入的改变,而修改导入的值,不会引起 foo.js 的改变,因为 CommonJs 使用的是值的拷贝。

require 查找细节
require 的语法规则为 require(X) ,其中 X 为一个模块名称或者路径。
如果 X 为一个核心模块,直接返回核心模块,并停止查找。
-
Node.js中的核心模块通常可分为http、fs、url、path、Events; -
这些内置模块的优势在于它们是由
C/C++编写,性能上优于脚本语言; -
在进行文件编译的时候,它们就被编译进二进制文件中。一旦
NOde开始执行,它们就直接加载到内存中,无须再次做标识符定位、文件定位、编译等过程,直接就可以执行。

如果 X 以 "./"、"../"、"/" 开头,如果 X 为一个文件夹路径名,则按照以下顺序查找:
-
查找
index.js文件; -
查找
index.json文件 -
查找
index.node文件
如果 X 为一个文件,且没有后缀名,则按照以下顺序查找:
-
查找
X.js文件; -
查找
X.json文件 -
查找
X.node文件
如果 X 不是路径也不是核心模块,则通过 node_module 所在的路径一层一层往下找,如果没有找到则报错提示没有找到:
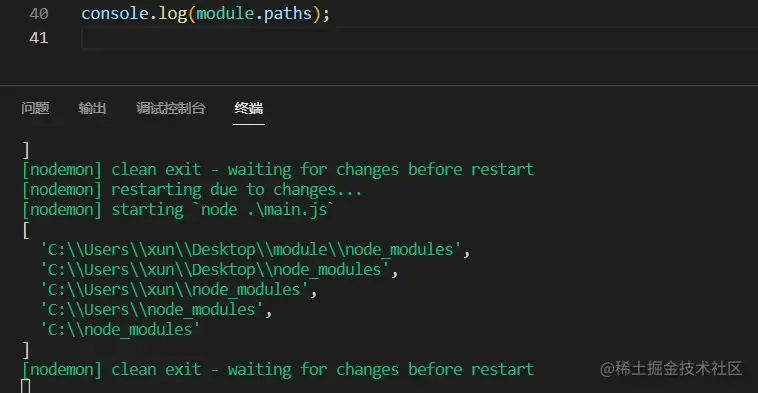

有了路径之后,下面就是 Module.findPath() 的源码,用来确定哪个是正确的路径,其中以下代码有省略的,具体代码可以查看 github :
Module._findPath = function (request, paths, isMain) {
// 如果是绝对路径,则不在搜索,返回空
const absoluteRequest = path.isAbsolute(request);
if (absoluteRequest) {
paths = [''];
} else if (!paths || paths.length === 0) {
return false;
}
// 第一步:如果当前路径已在缓存中,就直接返回缓存
const cacheKey = request + '\x00' + ArrayPrototypeJoin(paths, '\x00');
const entry = Module._pathCache[cacheKey];
if (entry) return entry;
let exts;
// 是否有后缀的目录斜杠
const trailingSlash = '...'; //省略了很多代码
// 是否相对路径
const isRelative = '...'; // 省略了很多代码
let insidePath = true;
if (isRelative) {
const normalizedRequest = path.normalize(request);
if (StringPrototypeStartsWith(normalizedRequest, '..')) {
insidePath = false;
}
}
// 遍历所有路径
for (let i = 0; i < paths.length; i++) {
const curPath = paths[i];
if (insidePath && curPath && _stat(curPath) < 1) continue;
if (!absoluteRequest) {
const exportsResolved = resolveExports(curPath, request);
if (exportsResolved) return exportsResolved;
}
const basePath = path.resolve(curPath, request);
let filename;
const rc = _stat(basePath);
if (!trailingSlash) {
if (rc === 0) {
// File.
if (!isMain) {
if (preserveSymlinks) {
filename = path.resolve(basePath);
} else {
filename = toRealPath(basePath);
}
} else if (preserveSymlinksMain) {
filename = path.resolve(basePath);
} else {
filename = toRealPath(basePath);
}
}
if (!filename) {
if (exts === undefined) exts = ObjectKeys(Module._extensions);
// 该模块文件加上后缀名,是否存在
filename = tryExtensions(basePath, exts, isMain);
}
}
if (!filename && rc === 1) {
if (exts === undefined) exts = ObjectKeys(Module._extensions);
// 目录中是否存在 package.json
filename = tryPackage(basePath, exts, isMain, request);
}
if (filename) {
// 将找到的文件路径存入返回缓存,然后返回
Module._pathCache[cacheKey] = filename;
return filename;
}
}
// 如果没有找打返回 false
return false;
};前面讲述了核心模块的原理,也解释了核心模块的引入速度为何是最快的,下图就展示了 os 原生模块的引入流程,可以看到,为了符合 CommonJs 模块规范,从 JavaScript 到 C/C++ 的过程是相当复杂的,他要经历 C/C++ 层面的内建模块定义、JavaScript 核心模块的定义和引入以及(JavaScript)文件模块层面的引入:
require 加载原理
有了模块的路径了,就可以加载模块了。但是有一个问题,require 是怎么来的,为什么平白无故能用呢,实际上都干了什么?
查看源码上发现.构造函数 Module 上有一个原型方法 require:
Module.prototype.require = function (id) {
// 进行简单的 id 变量的判断,需要传入的 id 是一个 string 类型。
validateString(id, 'id');
if (id === '') {
throw new ERR_INVALID_ARG_VALUE('id', id, 'must be a non-empty string');
}
// 默认为0,表示还没有使用过这个模块,每使用一次便自增一次
requireDepth++;
try {
// 用于检查是否有缓存,有则从缓存里查找
return Module._load(id, this, /* isMain */ false);
} finally {
// 每次结束后递减一个,用于判断递归的层次
requireDepth--;
}
};看完了 require 的了,我们再看看构造函数的静态方法 _load:
Module._load = function (request, parent, isMain) {
let relResolveCacheIdentifier;
if (parent) {
debug('Module._load REQUEST %s parent: %s', request, parent.id);
relResolveCacheIdentifier = `${parent.path}\x00${request}`;
// 以文件的绝对地址当成缓存 key
const filename = relativeResolveCache[relResolveCacheIdentifier];
reportModuleToWatchMode(filename);
if (filename !== undefined) {
// 先通过 key 从缓存中获取模块
const cachedModule = Module._cache[filename];
if (cachedModule !== undefined) {
updateChildren(parent, cachedModule, true);
if (!cachedModule.loaded)
// 如果要加载的模块缓存已经存在,但是并没有完全加载好,这是解决循环引用的关键
return getExportsForCircularRequire(cachedModule);
// 已经加载好的模块,直接从缓存中读取返回
return cachedModule.exports;
}
// 判断缓存是否存在父模块中,存在则删除
delete relativeResolveCache[relResolveCacheIdentifier];
}
}
// 判断是否为 node: 前缀的,也就是判断是否为原生模块
if (StringPrototypeStartsWith(request, 'node:')) {
// Slice 'node:' prefix
const id = StringPrototypeSlice(request, 5);
const module = loadBuiltinModule(id, request);
if (!module?.canBeRequiredByUsers) {
throw new ERR_UNKNOWN_BUILTIN_MODULE(request);
}
return module.exports;
}这个函数检查模块是否已经在缓存中——如果是,它返回 exports 对象。如果是 node: 前缀的内置模块,则调用 loadBuiltinModule() 返回结果。否则,创建一个新的模块,并保存到缓存中。
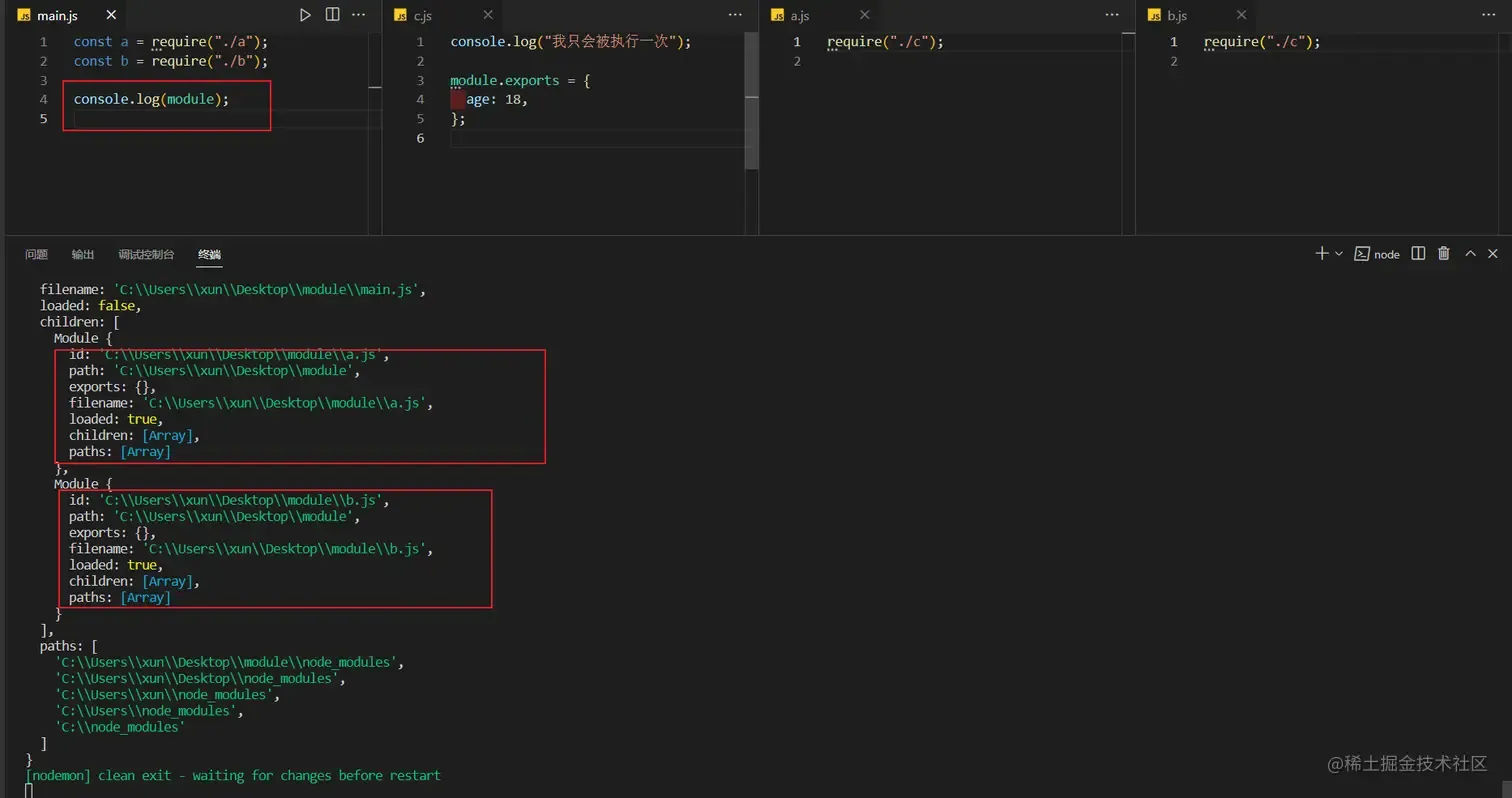
请看下面的一些例子:

通过查看输出,你会发现 c.js 文件只被执行了一次,那么为什么呢?这是因为每个模块都有一个 module 对象,其中有一个属性 loaded,如果被加载了,则为 true,也就是前面所说的被缓存过了,再次使用,不会再次执行,直接从缓存里面取,如果为 false,则执行一次并且添加到缓存中。
这就是 Node.js 通过缓存的方法解决无限循环引用的问题, 也是系统优化的重要手段,通过以空间换时间,使得每次加载模块变得非常高效。
优点也可能存在缺点,在实际的业务开发中,我们从堆的角度观察 node 启动模块后,缓存了大量的模块,包括第三方的模块,有的可能只加载使用一次。那么是否有必要增加一种模块的卸载机制(垃圾回收),可以降低对 V8 内存的占用,从而提升整体代码的运行效率。
commonJs 的编译
通过构造函数 Module 的原型方法 _compile 在正确的作用域或沙盒中运行模块的内容,并对外公开 require、module、exports等辅助变量。_compile 需要传入文件路径和被内置模块 vm 包装后的代码进行编译。
再次查看源码,抽取部分代码,这就是获取到模块文件后所做处理的核心代码:
// 将 module.exports 对象 赋值给 exports 这个作用前面有讲到过
const exports = this.exports;
// 又将 exports 对象 赋值给 thisValue
const thisValue = exports;
const module = this;
if (requireDepth === 0) statCache = new SafeMap();
if (inspectorWrapper) {
// inspectorWrapper 不知道是具体干啥的,就不硬解释了,
// 应该是把他合并成一个对象 然后最终对外暴露吧 没错,就是这样
result = inspectorWrapper(
compiledWrapper,
thisValue,
exports,
require,
module,
filename,
dirname,
);
} else {
result = ReflectApply(compiledWrapper, thisValue, [exports, require, module, filename, dirname]);
}
hasLoadedAnyUserCJSModule = true;
if (requireDepth === 0) statCache = null;
return result;require 的流程图正如下图所示:
总结
CommonJS 模块是同步加载的,这意味着模块的内容在所有依赖模块加载完毕后才会执行。尽管在浏览器中可能会引起阻塞,但在服务器环境中,由于模块通常存储在本地,加载速度较快,不会导致明显的性能问题。CommonJS 通过 module.exports 对象导出模块内容,并支持动态加载,确保每次加载的模块都被缓存,避免了循环引用问题。此外,CommonJS 模块采用缓存机制,require 加载的模块在后续调用中不会重新执行,任何对模块内容的修改也不会影响到原始模块实例。